OPENAI
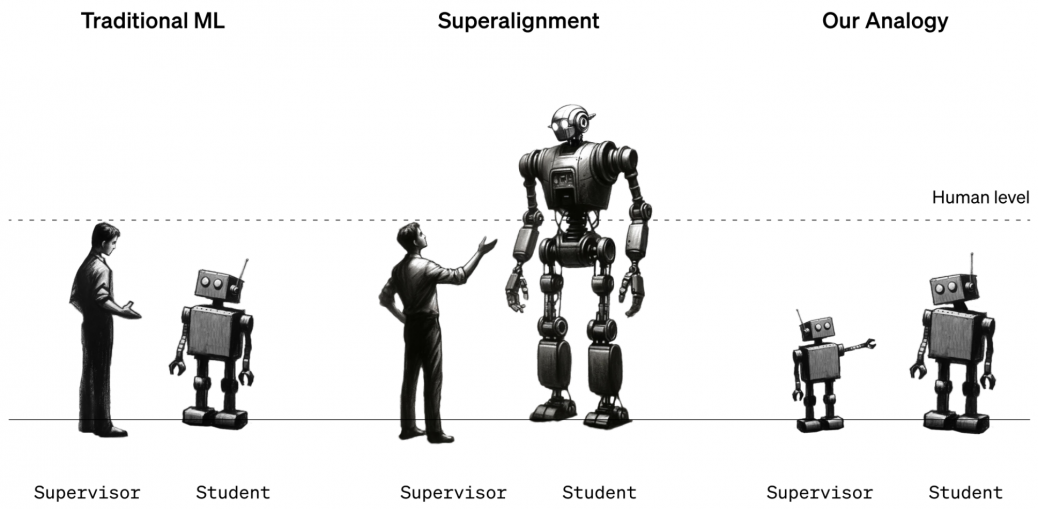
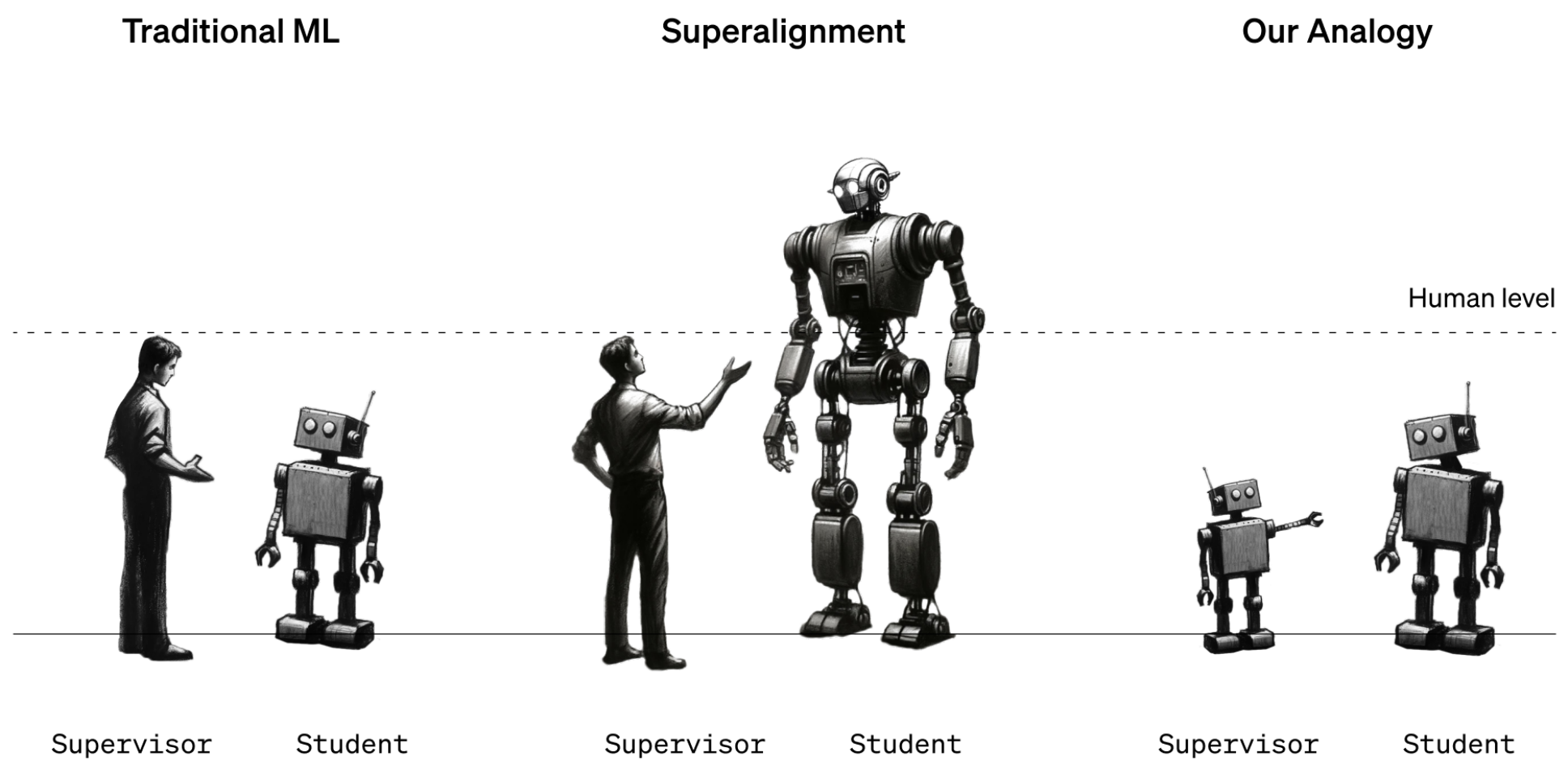
The researchers point out that the problem is hard to study because superhuman machines do not exist. So they used stand-ins. Instead of looking at how humans could supervise superhuman machines, they looked at how GPT-2, a model that OpenAI released five years ago, could supervise GPT-4, OpenAI’s latest and most powerful model. “If you can do that, it might be evidence that you can use similar techniques to have humans supervise superhuman models,” says Collin Burns, another researcher on the superalignment team.
The team took GPT-2 and trained it to perform a handful of different tasks, including a set of chess puzzles and 22 common natural-language-processing tests that assess inference, sentiment analysis, and so on. They used GPT-2’s responses to those tests and puzzles to train GPT-4 to perform the same tasks. It’s as if a 12th grader were taught how to do a task by a third grader. The trick was to do it without GPT-4 taking too big a hit in performance.
The results were mixed. The team measured the gap in performance between GPT-4 trained on GPT-2’s best guesses and GPT-4 trained on correct answers. They found that GPT-4 trained by GPT-2 performed 20% to 70% better than GPT-2 on the language tasks but did less well on the chess puzzles.
The fact that GPT-4 outdid its teacher at all is impressive, says team member Pavel Izmailov: “This is a really surprising and positive result.” But it fell far short of what it could do by itself, he says. They conclude that the approach is promising but needs more work.
“It is an interesting idea,” says Thilo Hagendorff, an AI researcher at the University of Stuttgart in Germany who works on alignment. But he thinks that GPT-2 might be too dumb to be a good teacher. “GPT-2 tends to give nonsensical responses to any task that is slightly complex or requires reasoning,” he says. Hagendorff would like to know what would happen if GPT-3 were used instead.
He also notes that this approach does not address Sutskever’s hypothetical scenario in which a superintelligence hides its true behavior and pretends to be aligned when it isn’t. “Future superhuman models will likely possess emergent abilities which are unknown to researchers,” says Hagendorff. “How can alignment work in these cases?”
But it is easy to point out shortcomings, he says. He is pleased to see OpenAI moving from speculation to experiment: “I applaud OpenAI for their effort.”
OpenAI now wants to recruit others to its cause. Alongside this research update, the company announced a new $10 million money pot that it plans to use to fund people working on superalignment. It will offer grants of up to $2 million to university labs, nonprofits, and individual researchers and one-year fellowships of $150,000 to graduate students. “We’re really excited about this,” says Aschenbrenner. “We really think there’s a lot that new researchers can contribute.”





{kind=link}
Recent Comments